Early in the second half of our second Earth orbit, while out of DSN contact, LCROSS experienced an anomaly. An error detected with our Inertial Reference Unit (IRU) resulted in an automatic response that consumed a large amount of propellant in a short amount of time. We spent the remainder of our second orbit recovering from that anomaly, and protecting against any future excessive propellant usage. We emerged safely, but with so little propellant remaining that, since that event, we’ve had to step very carefully to avoid wasting any more of this precious resource. This posting describes our discovery of the problem, and our recovery steps to protect LCROSS against a reoccurrence.
August 21/22 (DOY 234): Anomaly Detection, Spacecraft Safing, and Entry to Emergency Status
Shift A came into the Mission Operations Control Room (MOCR) on Saturday with a big agenda on LCROSS – to execute a third “Cold Side Bakeout” to rid the Centaur of more ice trapped in its skin, and to perform an Omni Pitch maneuver to flip the spacecraft to re-point the primary omni-directional antenna at the Earth, all under a tight schedule with little margin for error. The shift started at 2:25 AM Pacific time, but despite that early hour, we were excited to have such a challenging pass ahead of us, and eager to get started.
We acquired spacecraft telemetry at 3:25 AM. In the MOCR, each Flight Team operator sits behind a set of computer monitors that display fields of telemetry data – numbers, status indicators, etc. that indicate the health of LCROSS. Many of the telemetry data fields show up in stoplight colors – green, yellow, or red, to indicate whether the value is “nominal” (green), or approaching an emergency state (yellow), or is in an emergency state (red). Typically, telemetry comes up entirely green.
- The Inertial Reference Unit (IRU), our onboard gyro, and primary means of measuring rotation rates around each axis for attitude control, had faulted;
- The Star Tracker (STA) had replaced the IRU in providing rotation rate estimates to the attitude controller;
- Spacecraft rotation rates were periodically exceeding yellow high alarm limits (rotating too fast);
- LCROSS was firing thrusters almost continuously,
- The propellant tank pressure sensor (our primary means of determining how much fuel we have left), indicated we had consumed a LOT of propellant.
In short, we were in serious trouble, and needed to make corrections immediately.
First, we needed to save our remaining propellant by reducing our thruster firings. LCROSS has an Attitude Control System (ACS) to control its orientation automatically, by firing thrusters (LCROSS has no reaction wheels). The ACS controls each of the axes (roll, pitch and yaw; see the diagram in “First Orbit Around the Earth”) to within an acceptable error bound, defined by a control “deadband” from a fixed orientation in space. The ACS has several modes, all with different characteristics. The mode we were in, “Stellar Inertial Mode, deadband 2” (or “SIM DB2” for short), controlled each axis to a +/- 0.5 degree deadband. Through the anomaly, LCROSS was keeping to within its assigned deadband. Under attitude control with a deadband, thrusters typically fire most often when the spacecraft rotates to the very edge of the deadband, causing the spacecraft to stop its rotation and preventing it from exceeding the deadband limit. So, in an effort to slow down the firings (and our propellant consumption), we switched to a wider deadband, SIM DB3, which controls to a 10 degree range. Unfortunately, this didn’t reduce our thruster firing rate very much. We needed to do something else.
The anomaly had caused LCROSS to automatically switch from using the IRU to the Star Tracker (STA) for measuring spacecraft rotation rates. However, when we studied the output of the IRU, it was producing good rotation rate data (or just “rate data” for short). So, we ran through the IRU recovery procedure to re-engage the IRU with attitude control, and sure enough, that finally returned the thruster firing profile to normal and bought ourselves time to think.
One thing was immediately clear – we had suffered a significant “anomaly”, or bad problem and our plans for a Cold Side Bakeout and Omni Pitch maneuver were dashed. We’d be spending the rest of the shift, at least, and possibly a lot longer, figuring out what had happened and how to prevent it from ever happening again.
With the spacecraft stable, but still in jeopardy, the next order of business was to extend our DSN coverage. The Mission Operations Manager, with full agreement from the rest of the Flight Team, declared a “Spacecraft Emergency” with the Deep Space Network. Under DSN guidelines, we could only call this if we thought the spacecraft was in immediate jeopardy of partial or total mission failure. Under an emergency declaration, all missions using the Deep Space Network volunteer their normally-scheduled antenna time in a community effort to help the ailing mission. Their help provided LCROSS with enough antenna time to work out its problems.
As a step to protecting LCROSS, the Flight Team had to figure out what caused the anomaly. Since the spacecraft was healthy on our last contact, the anomaly had occurred while LCROSS was in a normally-scheduled 66 hour “out-of-view” period with the Deep Space Network (DSN). The Flight Team could not collect telemetry during that time. However, just for this purpose, LCROSS constantly records a part of its telemetry onboard, to enable our team to diagnose problems that happen while out of contact. We set immediately to “downlinking” and analyzing our virtual recorder telemetry data to gather clues.
Using this data, and over an hour or two of analysis, our team gradually pieced together the story. As with most anomalies, this one stemmed from multiple vulnerabilities whose combined harmful effects had not been anticipated.
In summary, a spurious, short-lived error on the IRU was interpreted as a more serious fault by the spacecraft fault management system, resulting in a switch to a backup rate sensor (STA). That rate signal was noisy (including random variations over the “true” rate signal), but was misinterpreted as real, “clean” rate data, causing over-control by the attitude control system and resulting in a great deal of propellant consumption. LCROSS detected the associated tank pressure drop, but with no fault management option available for disabling thruster control (thrusters are required to keep the LCROSS solar array pointed to the sun), and no ability to determine the specific nature of the pressure loss, the spacecraft fault management system performed steps to stop a leaking thruster (another potential reason for a pressure drop), and to power-up its transmitter to “phone home” to warn the operations team that there was a problem. However, this call could not be detected over the Southern hemisphere, since there were no DSN assets that could “see” LCROSS in that location, so the call was missed.
The LCROSS team knew that it had a serious problem on its hands. Did we have enough propellant to complete our mission? Was the IRU truly healthy, or would it fault again and trigger another loss of fuel? Thanks to the DSN Emergency Status agreement, LCROSS was able to get continuous ground antenna coverage, whenever the spacecraft was in view of one of the three DSN antennas. However, given our position in our Cruise Phase orbit, only the Canberra antenna complex could actually “see” LCROSS at that time, and only for 15 hours per day.
- To increase the “persistency” of the IRU fault check by flight software. By requiring an IRU fault to persist for 5 consecutive seconds rather than 1 second before tripping to STA, we hoped to avoid switching to the STA for an inconsequential IRU fault, yet remain protected against a serious IRU fault.
- To augment the IRU fault response by automatically recovering the IRU (as we had done manually) first, before switching to STA for rate information. Even if an IRU fault lasted for 5 seconds, this second-tier change would try to re-instate the IRU first, and fail over to the STA only if this had failed.
We designed, implemented, tested and loaded these changes to the spacecraft in our remaining time. By 1:50 PM Pacific Daylight Time, with these temporary fixes in place, we began configuring LCROSS for our forced DSN outage. Just 10 ½ hours after discovering our problem, we had to release our hold on LCROSS again and anxiously look to the next time when we would reacquire communications with the spacecraft.
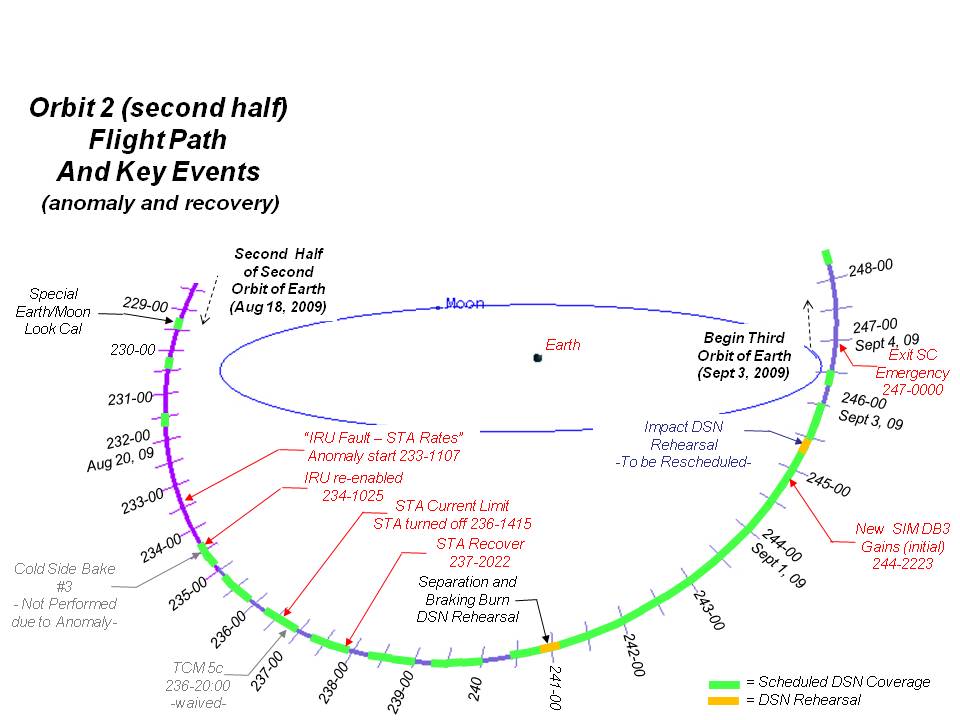
August 23 – September 3 (DOY 235 – 246): Our Recovery
- Improve our fault protection against an IRU failure for the long term. We had short-term fixes in place from the first day, but we ultimately needed to implement a more complete solution. These would take longer to design and test.
- Improve fault protection against further excessive propellant loss. This was a core issue. The loss of the IRU was one potential vulnerability, but there might be others we didn’t yet know about. LCROSS could not tolerate another similar loss of propellant.
- Determine whether the IRU was really showing signs of failure, or whether it was actually fine.
- Assess our propellant margin. Could we complete all of our mission objectives? Would we have to give up some of our planned activities to save propellant?
- Develop a plan for LCROSS health monitoring for the remainder of the mission. With so much at stake, we felt we needed a way to regularly monitor LCROSS after we emerged from Emergency Mode. However, with a team as small as ours, watching the spacecraft 24 hours a day for the rest of the mission would exhaust us. Besides, we needed to devote a lot of time in the coming weeks to prepare for impact.
- Continue performing the nominal events that could not be put off until our anomaly resolution was complete.
Propellant Usage Monitor and Free-Drift Mode
Our first priority was to develop fault protection against excessive propellant consumption. The sure way to save propellant is to not fire thrusters. But firing thrusters is the only way to maintain attitude control, and that is critical for generating solar energy and to keep the spacecraft thermally stable. It seemed we were in a bind. But then we recalled a strategy the team had originally designed to fight large Centaur gas leak torques (see the post entitled “Real-Life Operations: Day 3” for a description of the Centaur leak issue).
The attitude control system has a special safe mode called “Sun Point Mode” (SPM) that points the solar array at the sun using special Coarse Sun Sensors, and without the use of the Star Tracker. SPM spins LCROSS very slowly, end over end, but keeps the solar array pointed at the sun at all times. SPM still requires thruster control to maintain stability. However, through simulations, our engineering team discovered that by modifying SPM to spin faster, LCROSS would have enough angular momentum to keep it stable for a very long time.
We still needed a means to detect excessive propellant usage. We deemed propellant tank pressure measurements a little too coarse for such an important job, and yet there was no other single, direct indicator of propellant usage in the system. However, one of our team members came up with a great idea. LCROSS generates and stores special telemetry “packets” each time a thruster is fired. These packets accumulate over time in spacecraft memory, and are downloaded to Earth for analysis. His idea was to monitor the accumulation of thruster telemetry packets as an indirect indicator of propellant usage. It was unconventional, but the idea worked.
Efficient Control under Star Tracker Rates
IRU Healthy
Enough Propellant for Full Mission Success
There is no way to directly measure the amount of propellant left in the LCROSS tank. One can estimate the remaining propellant load by measuring pressure, temperature and tank volume (and compute the result using gas law equations), and alternatively one can estimate the propellant consumed through the mission by measuring the accumulated on-times for all the thrusters, along with predictions of how much propellant each firing consumes. Neither method is perfect.
The Mission Goes On
During our anomaly recovery, we had to support a number of activities that couldn’t wait until later. The day after our discovery of the anomaly (DOY 235, August 23), orbit geometry dictated we needed to rotate our spacecraft to re-point our omnidirectional antenna toward the Earth again, or suffer very poor communications for many days to come. We performed another of these 10 days later on DOY 246 (September 3).
In a bit of good news, TCM 5c, originally scheduled for DOY 236 (August 24), was determined to be unnecessary. As with so many TCM’s in our original plan, the Mission & Maneuver Design and Navigation teams planned TCM 5a so accurately that neither of the follow-up burns (TCM 5b and TCM 5c) needed to be performed.
However, not all of our news that day was good. Also on DOY 236, we thought we had also experienced signs of a failing Star Tracker. Out of concern for its survival, we shut down the STA for two days, and spent time away from our main anomaly recovery developing protections for the STA. As it turns out, the unusual STA signature was related to an onboard clock calibration we had just performed. The STA was just fine, but you can imagine, in the midst of the tension of the anomaly recovery, this extra scare didn’t help matters! As in so many cases with space flight, even seemingly benign changes can lead to unexpected results.
Negotiations with Deep Space Network and other Missions
To address the need to monitor LCROSS more often after our exit from Emergency Status, the LCROSS project negotiated a schedule with the DSN mission community that shortened all out-of-contact periods to 9 hours duration or less. This came at great impact to other missions, but was invaluable to LCROSS in achieving its Emergency Status exit criteria.
DOY 247 (September 4): Emergency Over
Twelve days after the anomaly discovery, having augmented LCROSS fault protection and our contact plan with the DSN and other DSN-supported missions, we requested that DSN remove LCROSS from Emergency Status.
One of the gratifying aspects of this effort was how the LCROSS team responded to make sure LCROSS stayed safe. Members of the Flight Team, LCROSS project and NASA Ames worked tirelessly. Northrop Grumman mobilized to provide a number of valuable improvements to LCROSS. The DSN mission community generously volunteered their antenna time to support our bid to restore LCROSS to nominal status. NASA management, from Headquarters to NASA Ames, provided constant support and valuable assistance.
I know this comment has nothing to do with the above article, but is the LCROSS impact going to be broadcast on the NASA channel (283) on Direct TV? I’d very much like to view it.
Thanks,
Rob Woolbright
Vancouver, WA
Paul: Thank you for compiling such an accurate summary of the anomaly and recovery. And thank you even more for the calm directions that you and Rusty provided to those of us manning the consoles during the emergency. It’s been an honor flying to the Moon with you, sir.
I watched the liftoff of LCROSS/LRO and have been tracking every update of this mission. I can’t help but to note the irony of saving a mission ultimately designed for total loss of both Centaur and LCROSS, but this is the kind of real science they never seemed able to pack into the Apollo missions, and missions like this are needed now and in the future to truly “push the envelope” of research, knowledge, and the word exploration in all of its fun and exciting forms. Most of all, my hat goes off to the LCROSS team which has done much with little, and by doing so they have re-energized my faith in NASA and its trademark “can do” spirit.
Now you MUST write a book about this!
🙂 Chris
Do we have any instruments on the moon that are backing up the maneuvers of the LCross here on earth?.
to keep it in the rigth track that is alot of work, jii!
Amazing that attitude control systems can still have problems like this. You’d think after 60 years they’d be tried & true drop in systems that just work. You can get hobbyist IRU’s for $40 nowadays. Hobbyists spend a lot of time working on basic flight control & figure the people who do aerospace for a living work on higher level problems.
I’ve been reading your posts with anticipation and interest since launch, but none more awaited than your descripition of the ‘anomaly’, your previous post to this left us hanging,,, Well done to all the crew. Now enjoy the fruits of your labour and nail it into the Cabeus crater..
cheers from Australia.
I appreciate the effort the entire team brings to this mission. It is as interesting hearing about the challenges along the way as it will be the results themselves. As a software developer, I know the impact that a small team of dedicated engineers can have in accomplishing daunting tasks. Wish everyone the best in the final hours of the mission and look forward to hearing the results. Any idea on how long the analysis will take from impact to conclusion, if water does or does not exist and with what level of certainty?
Thanks!